Montando 5 gráficos com uma métrica do Prometheus
Publicado em 20 ago 2020. Uns 10 minutos de leitura.
A linguagem de consultas do Prometheus, a PromQL, permite fazer transformações e agregações das métricas para extrair dados que não haviam sido reportados diretamente pela aplicação mas podem ser deduzidos. Nesse post, trago 5 consultas diferentes que podemos fazer para monitorar nossas aplicações usando apenas (tecnicamente) uma métrica! Vamos usá-las para montar gráficos no Grafana.
Eu digo tecnicamente pois vamos usar uma métrica do tipo histograma, que é um tipo complexo de métrica do Prometheus. Por baixo, um histograma é implementado usando várias séries temporais distintas, mas a biblioteca de cliente do Prometheus abstrai isso e a aplicação só precisa registrar cada evento em uma única métrica.
A métrica que vamos usar vai registrar a distribuição da latência das requisições HTTP que a aplicação recebe, em segundos. Vamos chamá-la de http_request_duration_seconds. Para conseguirmos fazer algumas agregações que queremos, vamos adicionar duas dimensões a essta métrica: path que é o caminho (ou endpoint) da requisição e status_class que é que tipo retorno foi dado a essa requisição, como 2XX, 4XX, 5XX, e por aí vai.
A criação e registro dos eventos dessa métrica depende da linguagem e framework que você esteja usando. Alguns frameworks possuem integração com a biblioteca de cliente do Prometheus para a linguagem e podem já fornecer uma métrica como essa. Do contrário, você precisa observar as requisições que chegam e reportar uma métrica de histograma passando como valor o número de segundos que ela levou para terminar e, como dimensões, pelo menos as duas acima.
Sobre o path, é importante lembrar que dimensões (labels) no Prometheus não podem ter valores ilimitados, pois isso gera uma carga considerável nele. Uma regra de ouro é: se você não consegue listar todas as possibilidades de valores pra uma dimensão, ela não deveria existir. Para o path, isso quer dizer que temos que tomar cuidado com interpolações. Por exemplo, se a aplicação tem uma rota /api/users/812376/profile, em que 812376 representa um ID de usuário, devemos reportar o caminho sem interpolações, como /api/users/:id/profile.
Sobre o status_class, ele é uma abstração em cima do código de status da resposta da nossa aplicação. Por exemplo, se a aplicação retornar 200 ou 201, o status_class seria 2XX. Se retornar 500 ou 503, seria 5XX. Isso vai facilitar, por exemplo, filtrarmos todas as requisições em que o servidor deu um erro (5XX) sem ter que listar todos os possíveis códigos de erro HTTP.
Duas observações antes de começar: algumas dessas métricas, medidas do ponto de vista da aplicação, serão naturalmente enviesadas pois considerarão apenas requisições que chegaram a aplicação e foram respondidas (mesmo que com um erro 500). Porém, se a aplicação estiver mal das pernas, ela pode começar a derrubar conexões, ficar indisponível para reportar métricas, ou ainda um balanceador de carga que sirva a aplicação comece a enfileirar requisições e eventualmente desistr delas. Se você conseguir métricas assim do load balancer, pode ter uma figura mais verídica nos momento de maior aperto.
Similarmente, se você conseguir coletar métricas no cliente (navegador, aplicativo, etc), você consegue considerar falhas em requisições por razões como problemas de DNS, que nem chegariam no seu load balancer. É também possível ver latência real incluindo o tempo gasto pela conexão de rede do usuário, o que é interessante de analisar pois, mesmo que você não consiga influenciar muito a velocidade de conexão dessa pessoa usando 3G com um pontinho de sinal, entender esse comportamento pode ajudar a otimizar seu conteúdo para as condições mais típicas do seu usuário.
Percentis de latência
Começando por uma das aplicações mais comuns para histogramas no Prometheus: estimar percentis. Para isso, usamos a função histogram_quantile que espera um número de 0 a 1 (por exemplo, 0.5 é o percentil 50, ou mediana).
Para esta métrica, queremos ver os percentis de latência para a aplicação toda, independentemente do endpoint ou código de retorno. Então vamos agrupar nossa série temporal usando sum. Sempre que agregamos séries que vão ser usadas para a função histogram_quantile, precisamos manter a label le (mais sobre isso no post sobre tipos complexos de métricas).
histogram_quantile(0.99, sum(rate(http_request_duration_seconds_bucket[5m])) by (le))histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket[5m])) by (le))histogram_quantile(0.5, sum(rate(http_request_duration_seconds_bucket[5m])) by (le))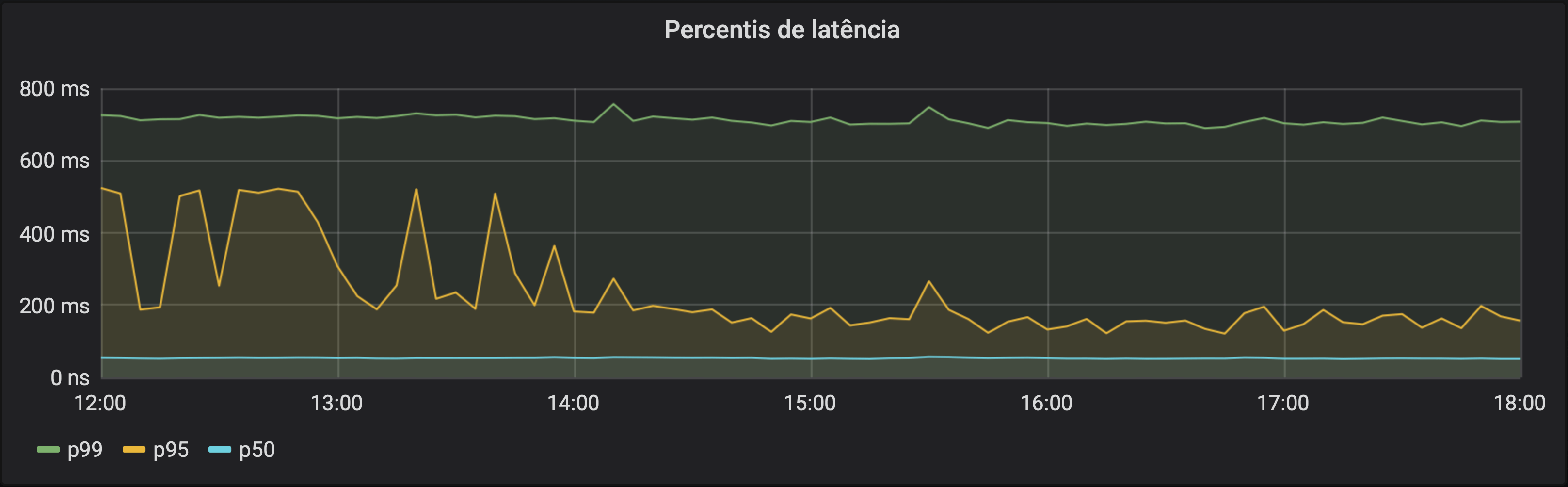
Cada consulta acima vai retornar uma série que representa o percentil de latência (99, 90 e 50, respectivamente). Como para o cálculo precisamos usar a função rate, precisamos de uma janela para o cálculo da métrica. Em todos os exemplos deste post vou usar 5 minutos. Esse valor tem que ser, no mínimo, maior que o dobro do intervalo entre coletas de métrica do Prometheus (scrape_interval na configuração), pois você precisa de dois pontos de dados para calcular a variação.
Latência média
Métricas de histograma incluem, além das séries temporais dos buckets, duas séries a mais que contém a soma de todos os valores e a quantidade de valores registrados. Podemos usar essas séries para pegar a média aritimética dos valores. A média pode ser fortemente influenciada por valores extremos, e a análise de percentis é útil para evitar essa influência. Mas, se quisermos uma média aritimética, podemos obetê-la:
sum(rate(http_request_duration_seconds_sum[5m]))
/
sum(rate(http_request_duration_seconds_count[5m]))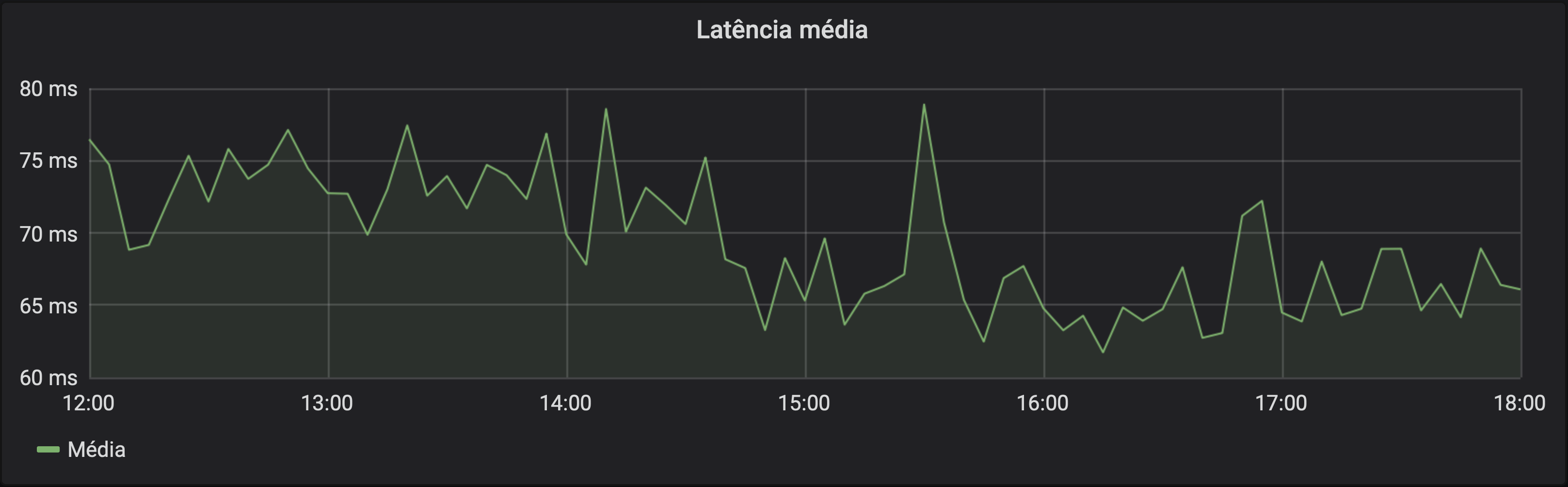
Para fazer essa consulta, além de dividir a soma pelo total (que é a definição de média aritimética), estamos usando a função rate. Ela serve neste caso para que nosso gráfico não considere todas os eventos da história. Sem o rate, vamos calcular a latência média desde que a aplicação iniciou, e não uma média "instantânea" (que não é instantânea de fato pois precisamos de uma janela para calcular a média, neste exemplo, de 5 minutos).
Com o rate, vamos pegar o quanto a soma dos valores cresceu nos últimos 5 minutos e dividir por o quanto a quatidade de eventos cresceu nos últimos 5 minutos. Assim, cada ponto da série temporal resultante é a latência média dos últimos 5 minutos.
Disponibilidade (em sucessos/total)
Dependendo do conceito de disponibilidade que você utiliza, a maneira que construimos essa métrica serve para fazer uma medição de disponibilidade da sua aplicação. Uma das definições, citada no livro de SRE do Google, é a de disponibilidade agregada. Ela parte da ideia de que o uptime (tempo em que o serviço estava disponível) pode ser menos relevante do que a quantidade de requisições com sucesso que a aplicação atendeu.
Se uma árvore cai numa floresta deserta e ninguém escuta, ela faz barulho? Se a sua aplicação passa 5 minutos offline mas ninguém tentou interagir com ela na quele momento, isso importa? Ficar 5 minutos fora do ar às 3 da manhã e ao meio-dia para uma aplicação de delivery de comida são situações bem diferentes.
Dado que nossa métrica tem uma dimensão de status_class e uma série temporal que representa a quantidade de requisições que aconteceram (a _count), podemos calcular o percentual de disponibilidade instantânea dela dividindo a quantidade de erros pelo total de requisições. Como queremos saber o percentual de requisições que não deu erro, vamos pegar como resultado 1 - percentual-de-erros.
1 -
sum(rate(http_request_duration_seconds_count{status_class="5XX"}[5m]))
/
sum(rate(http_request_duration_seconds_count[5m]))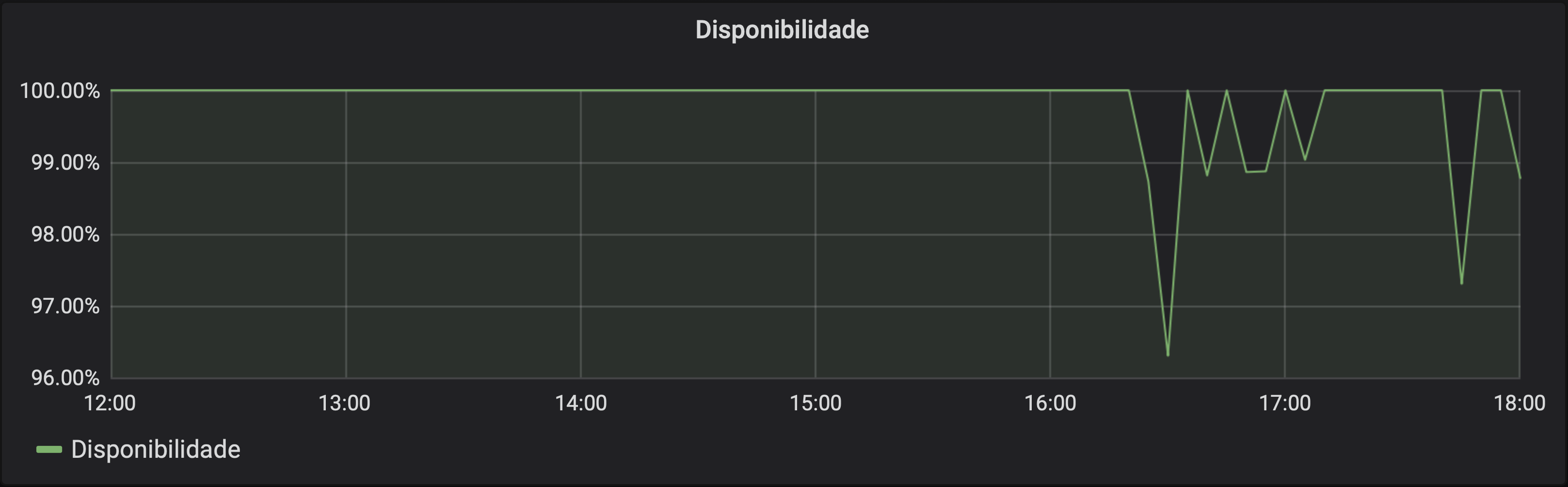
Podemos usar janelas maiores, que mais fazem sentido olhando números do que gráficos. Podemos ter um painel no Grafana representando, por exemplo, a disponibilidade nas últimas 24 horas mudando apenas o tamanho da janela.
1 -
sum(rate(http_request_duration_seconds_count{status_class="5XX"}[24h]))
/
sum(rate(http_request_duration_seconds_count[24h]))
Top endpoints mais problemáticos (percentual)
Podemos reutilizar algumas consultas que fizemos acima, com uma agregação por path, para comparar a performance de diferentes endpoints da aplicação. Numa aplicação muito grande, a lista de endpoints pode ser muito extensa (mesmo tomando cuidado para não inserir interpolações nela), e podemos usar a função topk para diminuir essa lista. Como o nome diz, ela retorna os k maiores valores.
Vamos usar a mesma consulta do terceiro exemplo, mas adicionando um agrupamento da agregação de soma, by (path), para termos um percentual de falha para cada endpoint e, com o topk, pegar os 10 maiores percentuais.
topk(10,
sum(rate(http_request_duration_seconds_count{status_class="5XX"}[5m])) by (path)
/
sum(rate(http_request_duration_seconds_count[5m])) by (path)
)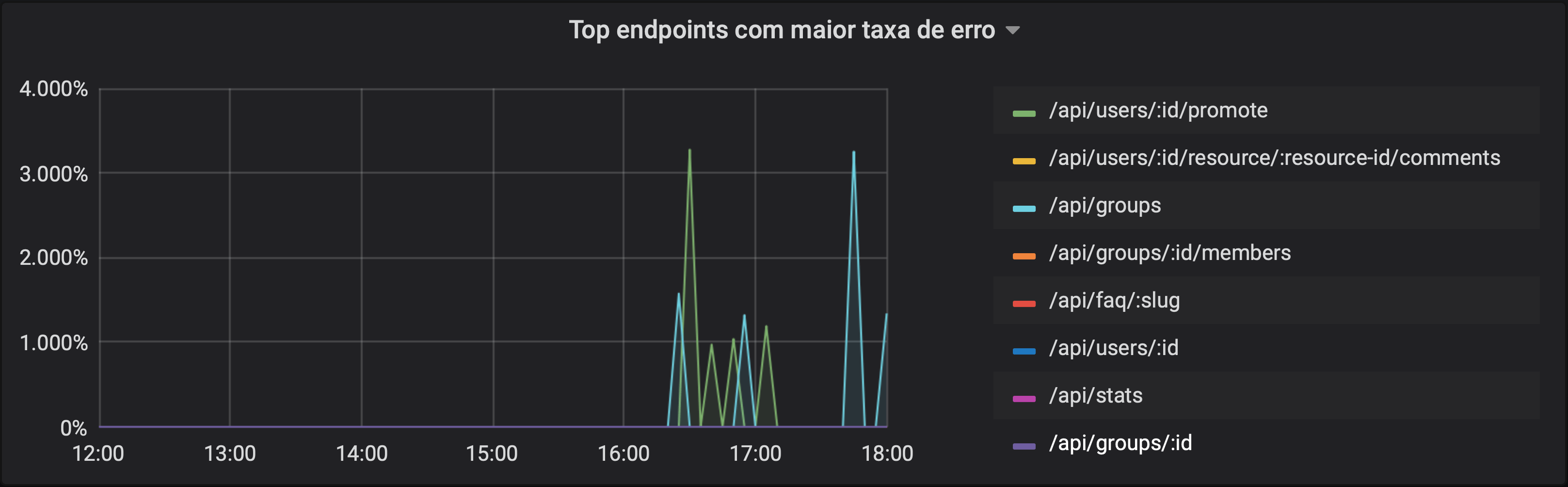
Neste exemplo, usamos essa função para montar um gráfico. Note que, neste caso, ela pode retornar mais do que k séries pois, em algum momento do gráfico, uma série pode deixar de existir pois seu valor não está mais entre os k primeiros e, similarmente, novas séries podem surgir. Você pode também formatar essa consulta como uma tabela e olhar apenas para o valor mais recente, que certamente vai conter (no máximo) k linhas. No exemplo abaixo, apenas dois endpoints estavam reportando algum erro nos últimos 5 minutos e, por isso, só há duas linhas na tabela:

Top endpoints mais lentos (percentil)
Seguindo a mesma lógica do exemplo anterior, mas usando a consulta do primeiro exemplo, podemos pegar a lista dos 10 endpoints com os maiores percentis-99 de latência. O Grafana também permite adicionar valores nas legendas. No gráfico abaixo, eu coloquei para mostrar o valor mais recente e ordernar a legenda por esse valor, mostrando os endpoints mais lentos no momento, em ordem, na legenda.
topk(10,
histogram_quantile(0.99, sum(rate(http_request_duration_seconds_bucket[5m])) by (le, path))
)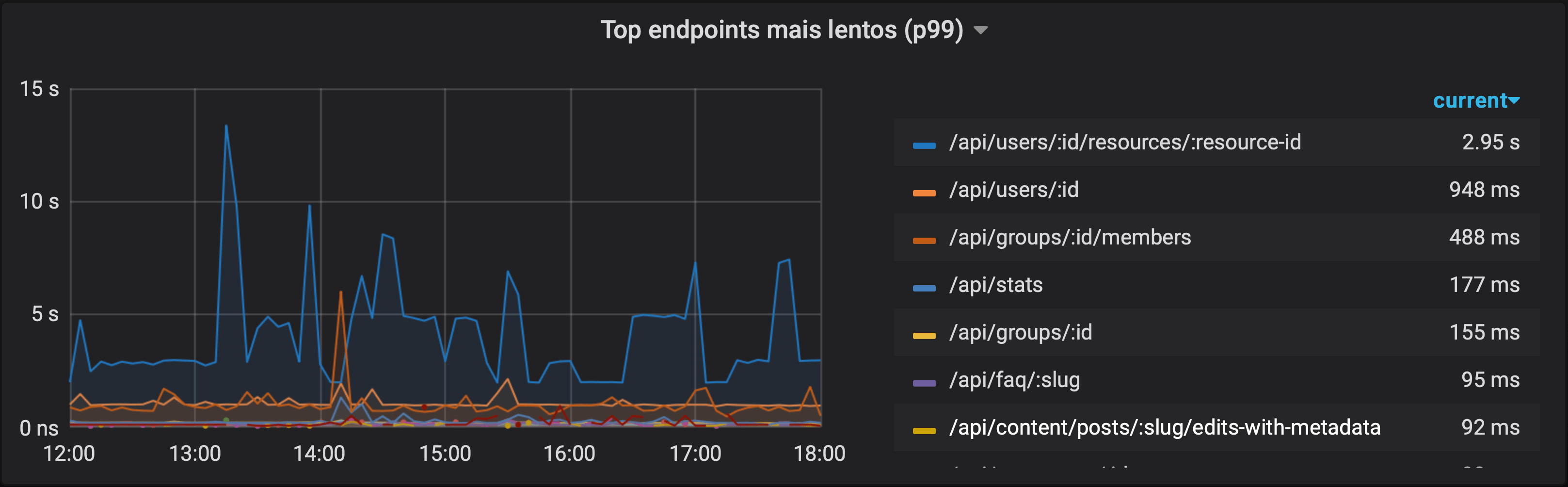
Lembrando que é importante manter a dimensão le na agregação sempre que formos usá-la dentro de um histogram_quantile.
Assim como no exemplo anterior, montar um gráfico usando topk pode retornar mais de k séries. Além de usar uma tabela, é possível montar um gráfico evitando mostrar mais de k séries isso, tomando uma decisão de quais séries retornar, em um momento do tempo, e depois consultando apenas essas séries. Há um exemplo disso neste post da Robust Perception.
Pra fechar, vale comentar que a gente não precisa ter apenas uma métrica na aplicação. É perfeitamente aceitável criar uma métrica para medir o histograma das latências e uma outra para medir o número de requisições, com separação por status de retorno e outras dimensões. Para esse post, eu me aproveitei de que todo histograma traz consigo um contador de ocorrências e adicionei as labels que precisávamos para montar os gráficos acima.
Essas consultas podem ser usadas não só para montar gráficos bonitos no Grafana, mas também para criar alertas usando o Alert Manager, componente do Prometheus que roda consultas nele e gera alertas caso essas consultas retornem algum estado em particular. Quais métricas usar para alertar e como definir bons alertas são assuntos interessantes para tratar em posts futuros! :)
Gostou? Que tal compartilhar?